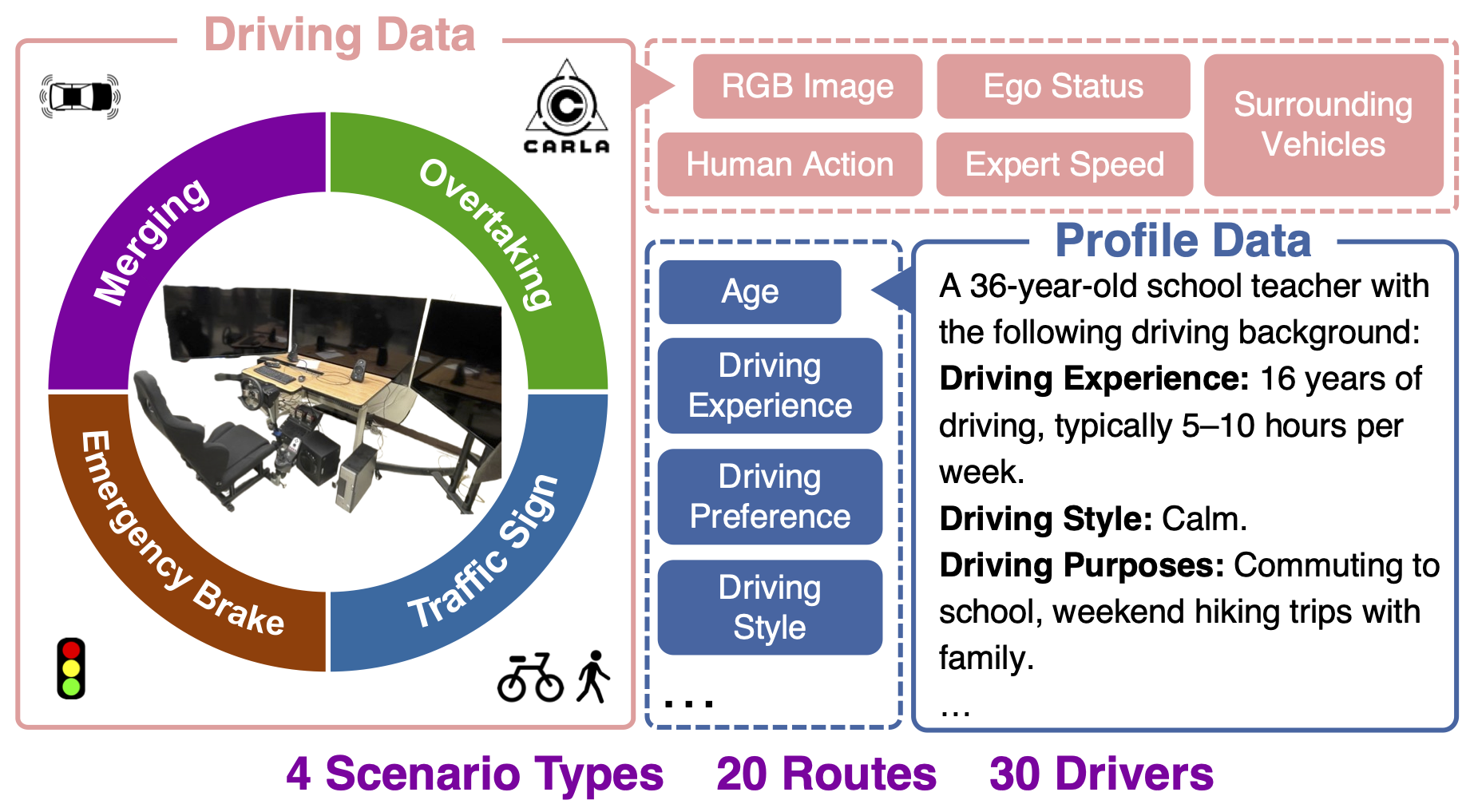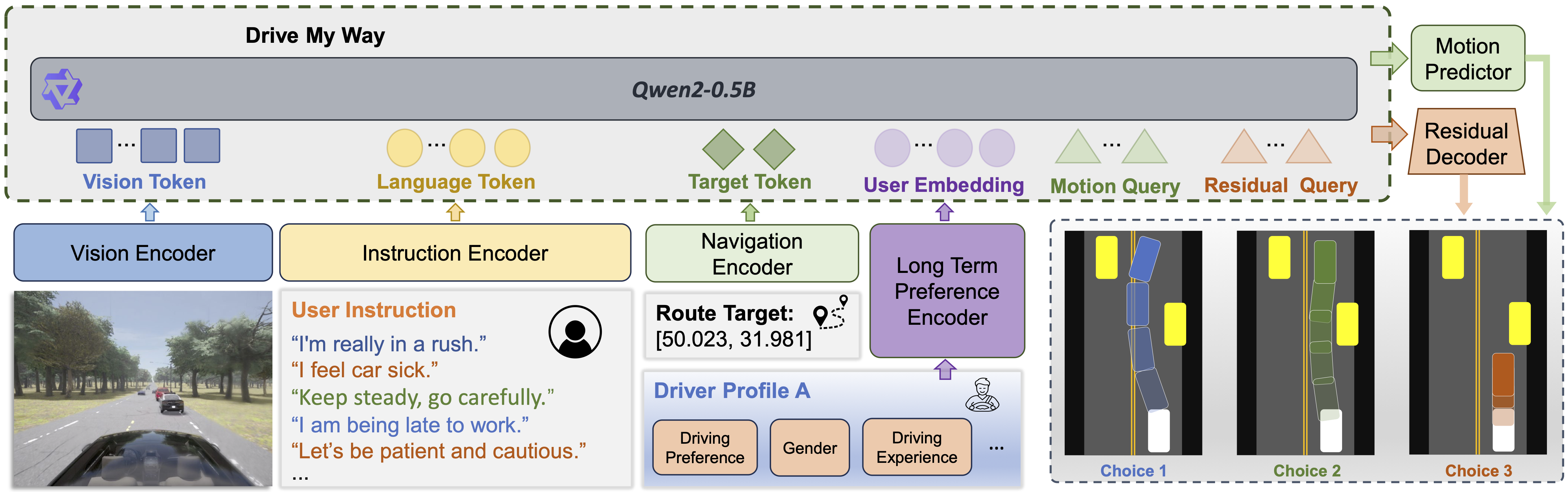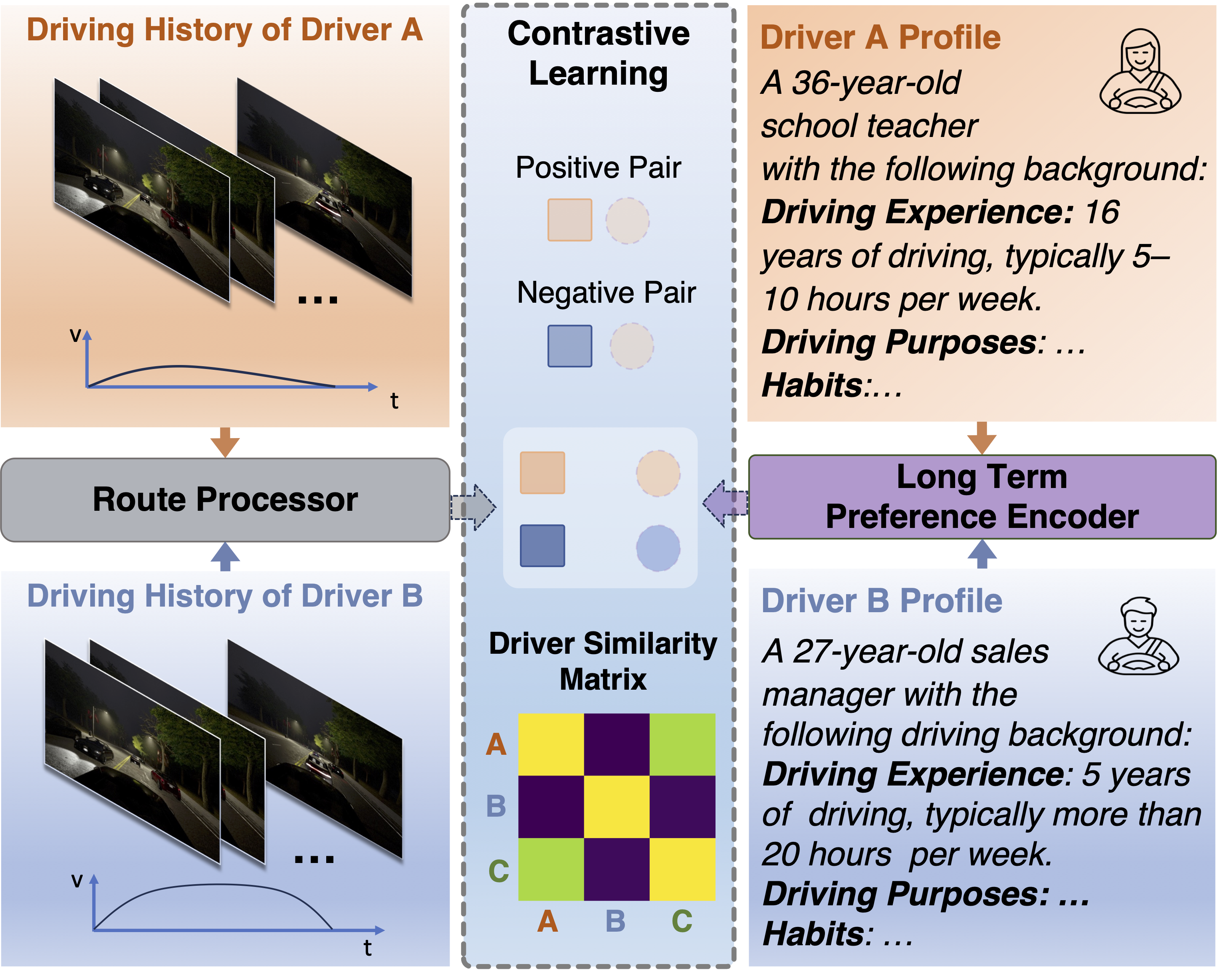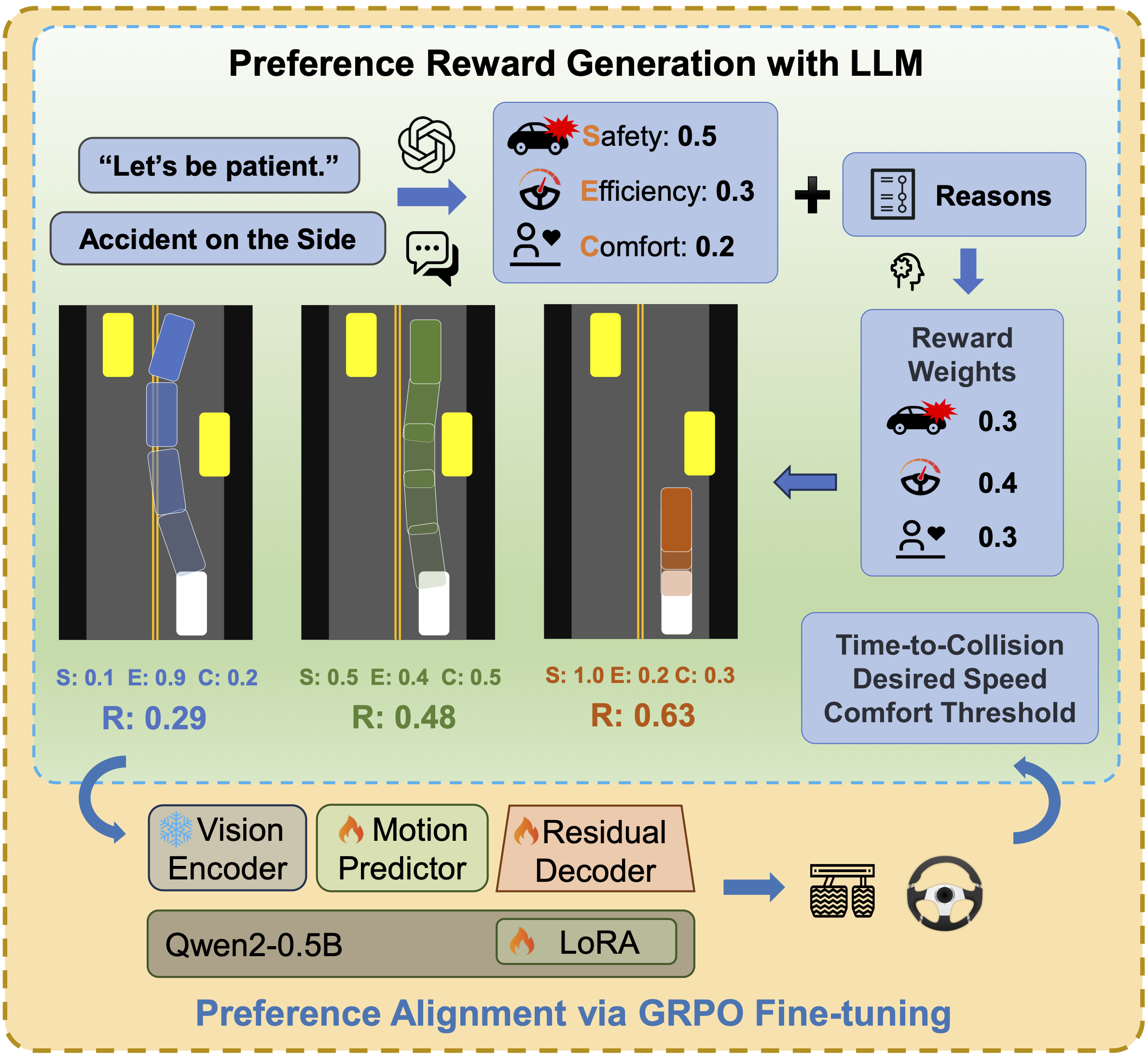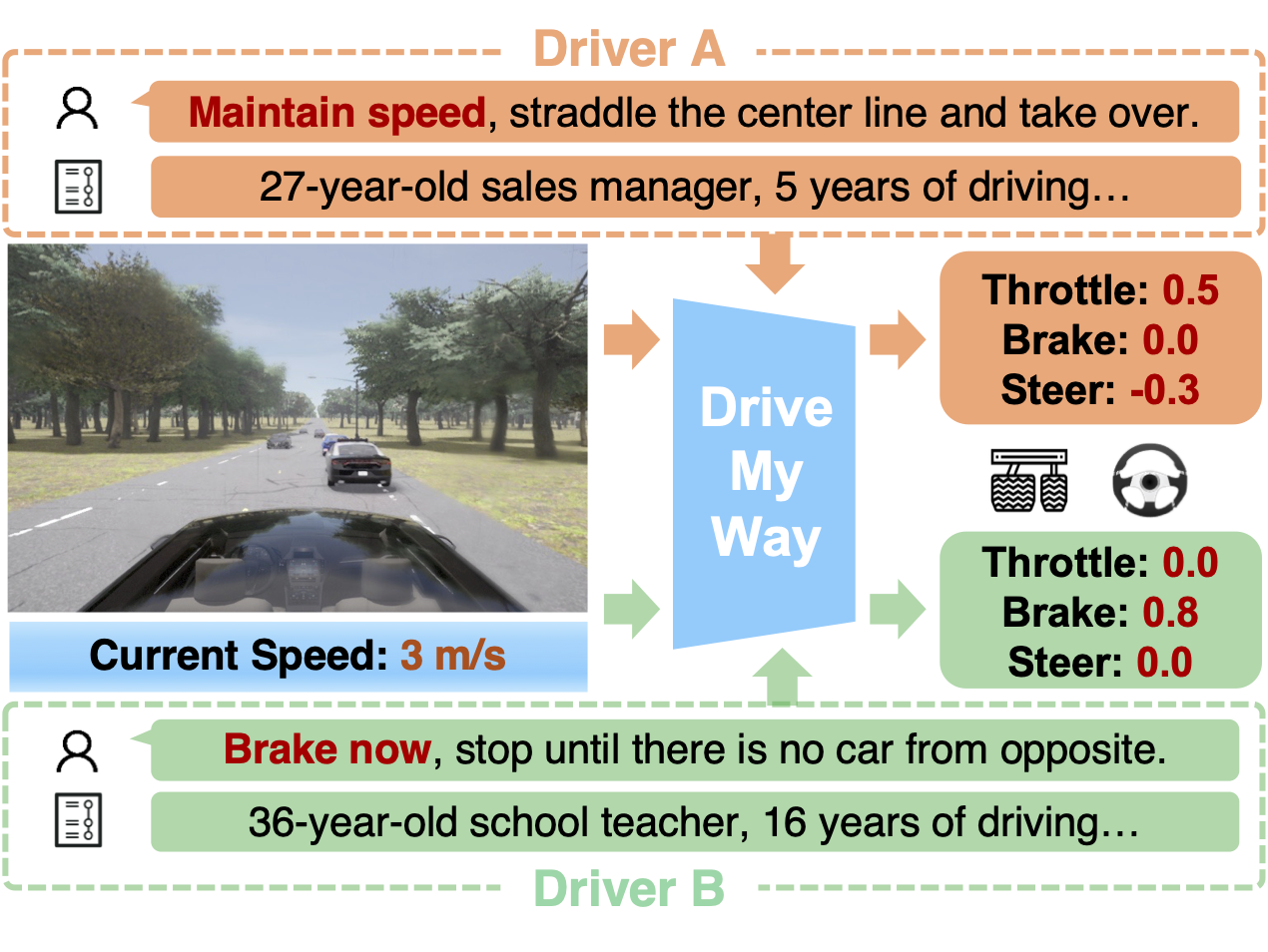
Human driving behavior is inherently personal and continuously evolving.
Drivers exhibit stable, long-term habits while also adjusting their behavior in the moment based on short-term intent and situational context.
What are the limitations of current systems?
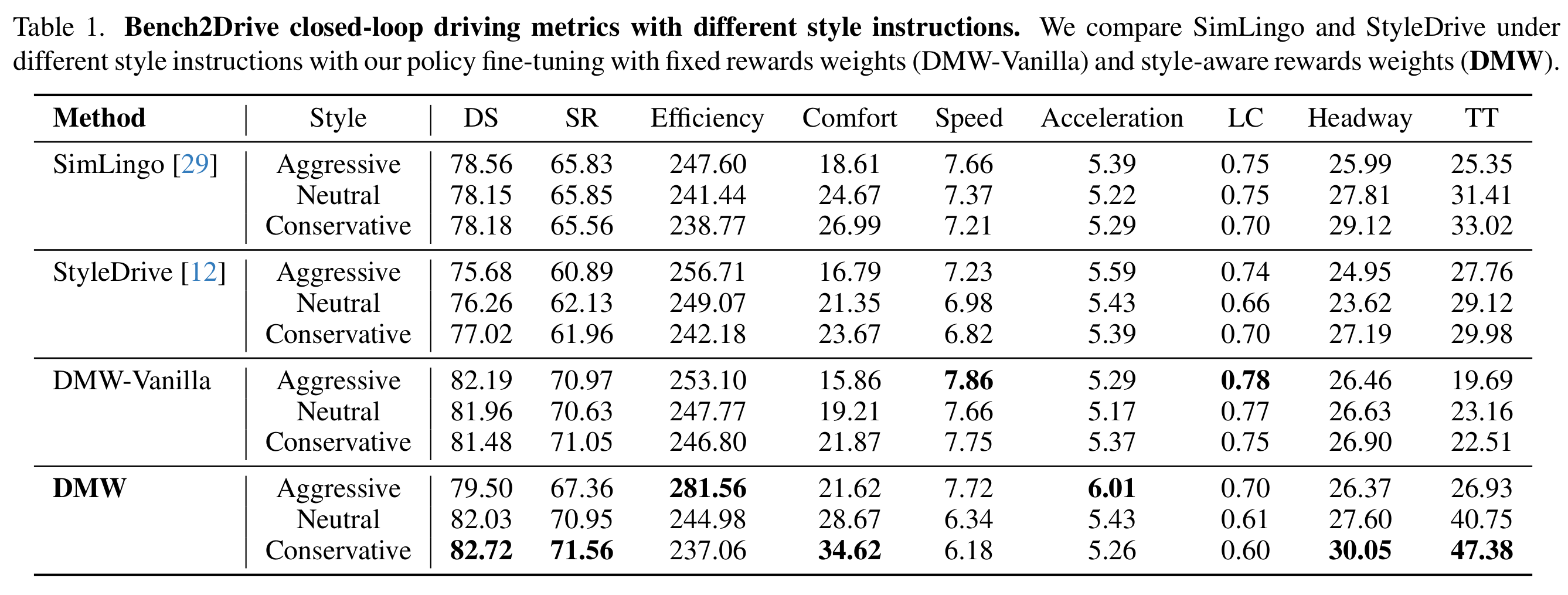
Most end-to-end autonomous driving systems optimize a generic objective
(e.g., safety/efficiency), effectively targeting an “average driver.”
Some provide a small set of predefined modes (e.g., sport, comfort, eco),
but these coarse presets cannot represent the nuanced, consistent differences in individual driving styles.
In addition, they are not designed to interpret and follow natural-language intent specified at runtime.
Why previous personalized driving systems fall short.
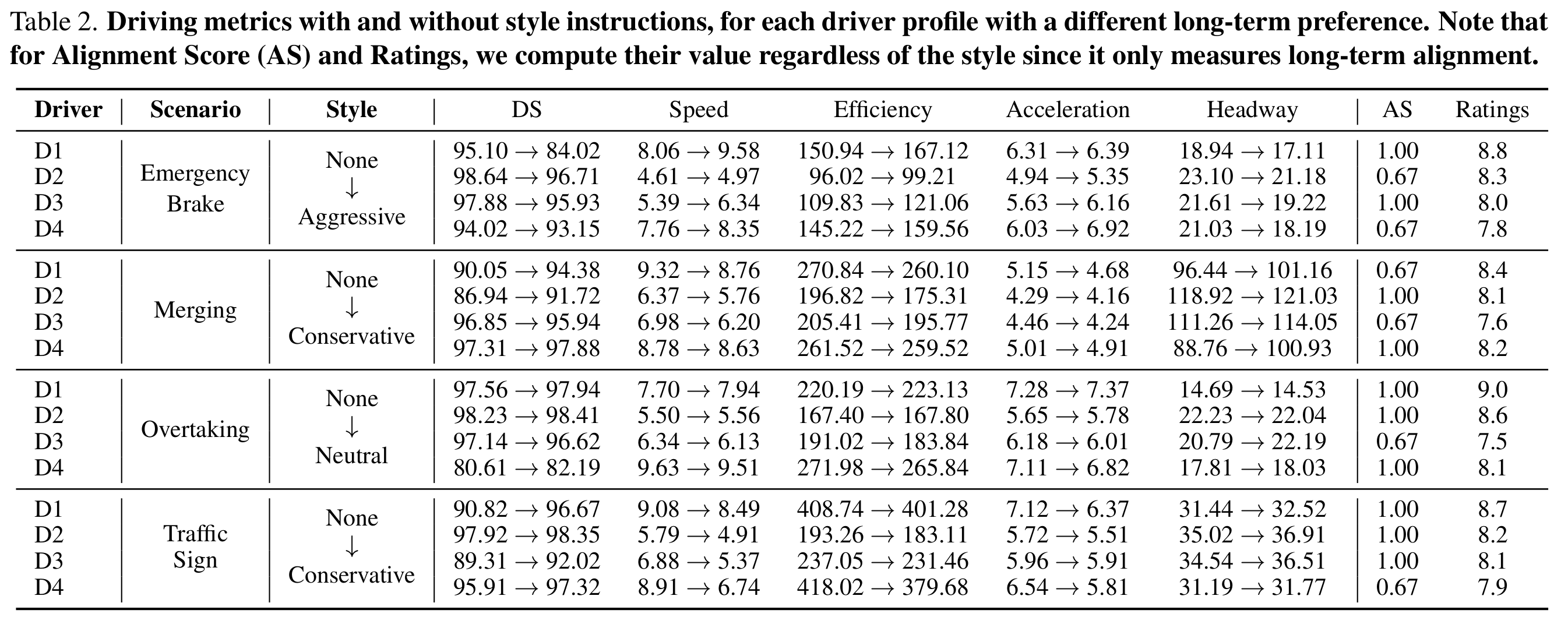
Existing personalized-focused driving works mainly fall into two categories.
First, data-driven approaches extract predefined driving styles from human
demonstrations and learn style-conditioned policies. These methods rely on a fixed and limited set of driving styles and scale poorly
to a growing population of users with diverse preferences.
Second, language-driven approaches leverage large language models (LLMs) for
instruction-based personalization, typically requiring learning from explicit
human driver feedback. Such approaches introduce interaction costs and remain constrained to simple, low-interaction settings.
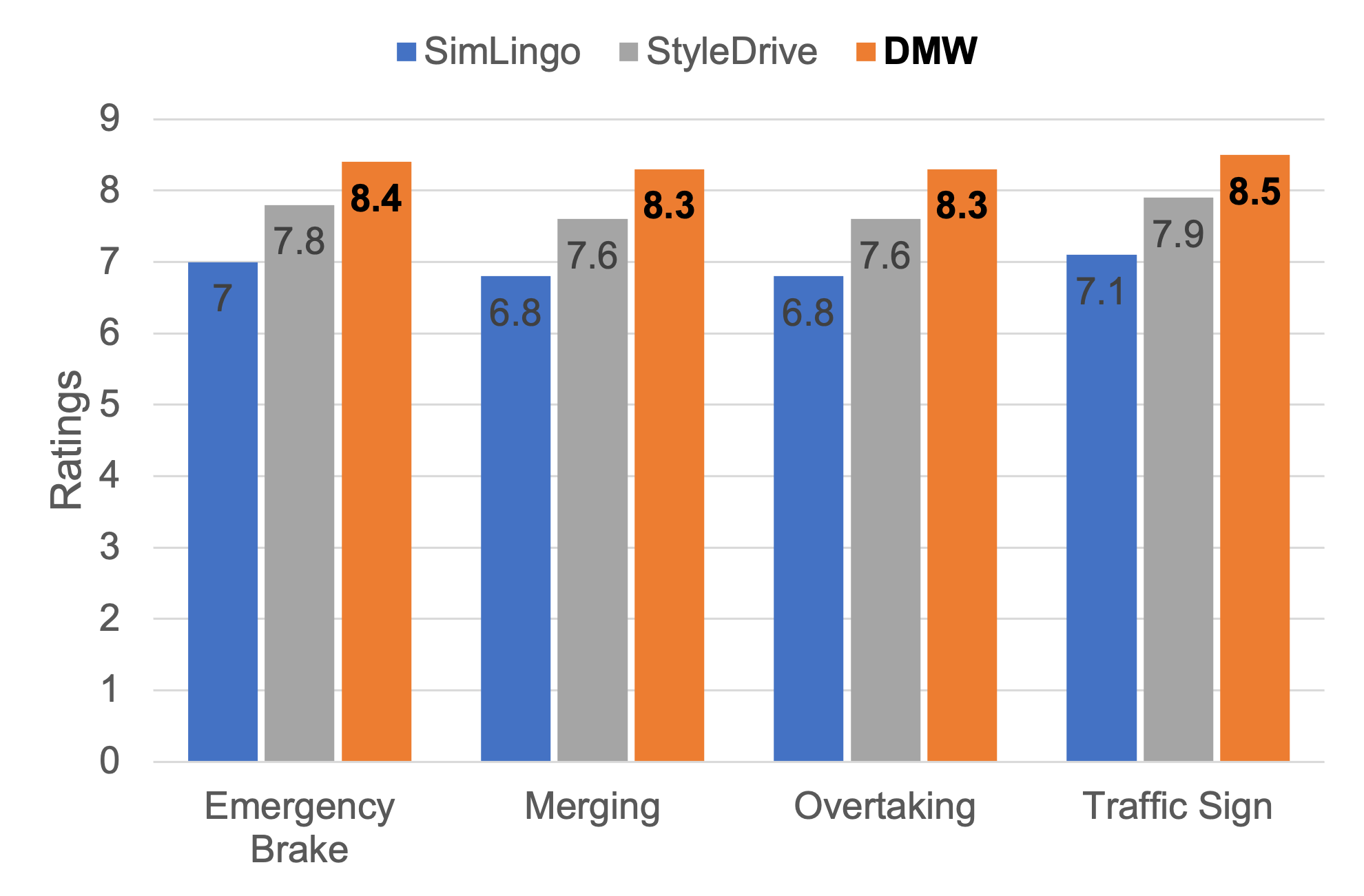
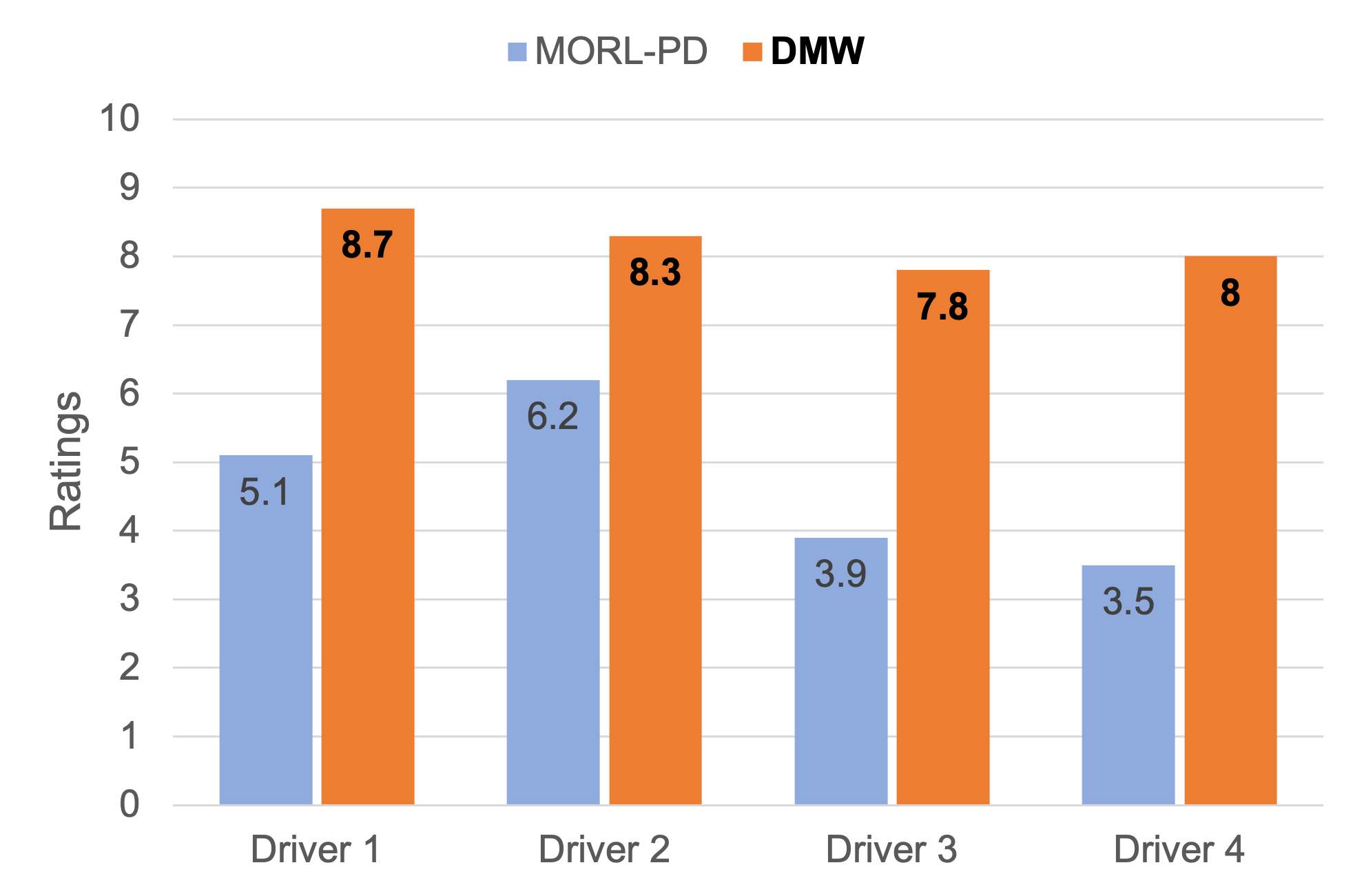
Core idea:
DMW aligns the VLA policy with long-term driving patterns and real-time preference instructions to produce behaviors that are safe and effective,
yet also recognizable and adaptable.
 Drive
My
Way
:
Preference Alignment of Vision-Language-Action Model for Personalized Driving
Drive
My
Way
:
Preference Alignment of Vision-Language-Action Model for Personalized Driving